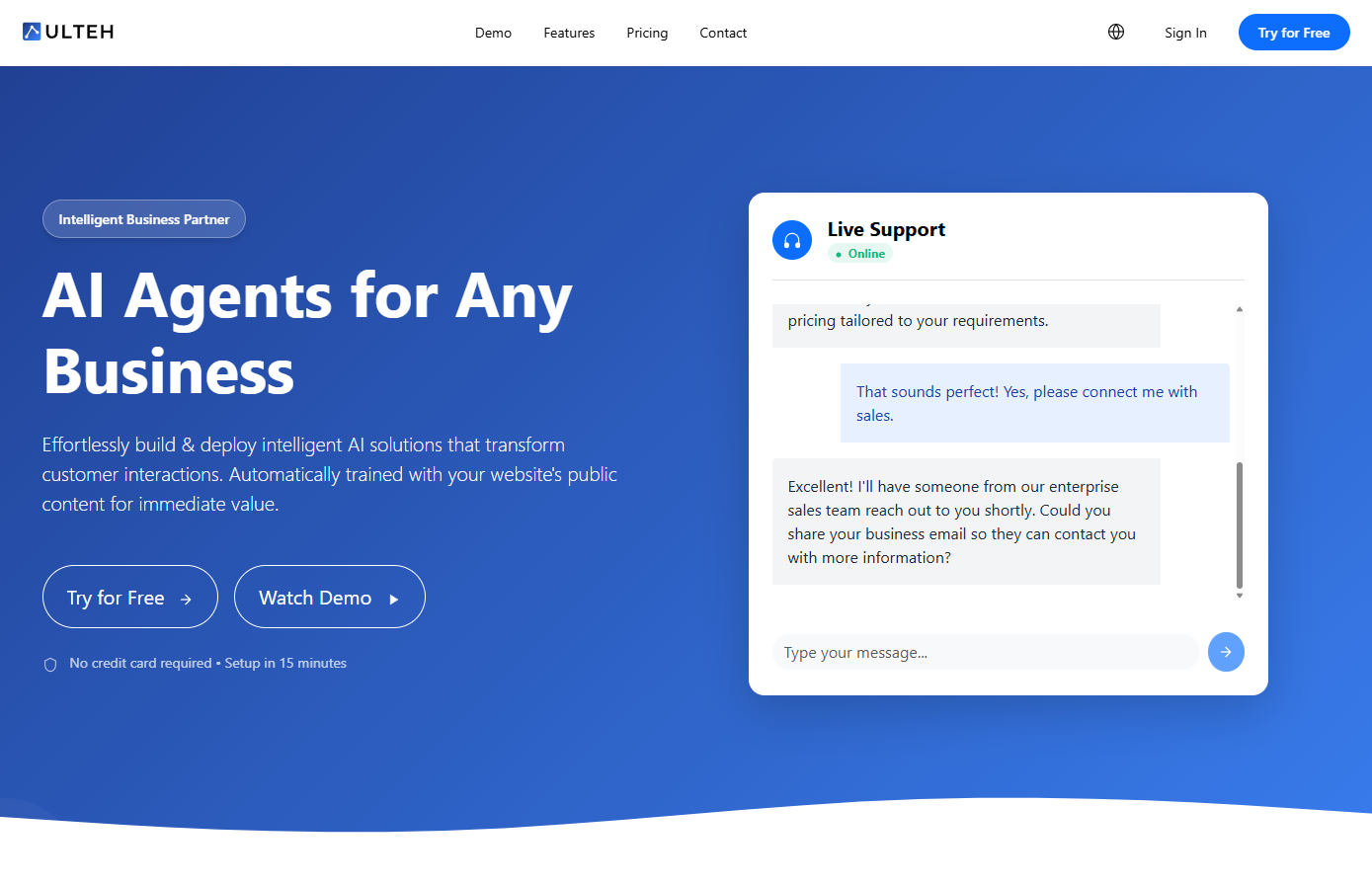
Test AI on YOUR Website in 60 Seconds
See how our AI instantly analyzes your website and creates a personalized chatbot - without registration. Just enter your URL and watch it work!
Ready in 60 seconds
No coding required
100% secure
The Evolution of Human-Computer Interaction
When I first encountered a voice assistant back in 2011, it was little more than a novelty—something to ask silly questions or set basic timers. The responses were robotic, the comprehension limited, and the experience ultimately frustrating. Fast forward to today, and the transformation is remarkable. Voice-enabled AI has evolved from those rudimentary beginnings into sophisticated multimodal systems that combine speech recognition, natural language understanding, visual processing, and contextual awareness.
This evolution represents one of the most significant shifts in human-computer interaction since the graphical user interface replaced command lines. For decades, we adapted our behavior to accommodate technology's limitations—typing precisely formatted commands, navigating complex menu structures, and learning specialized interfaces. Now, technology is finally adapting to our natural communication methods.
The rise of multimodal chatbots—AI systems that can process and respond through multiple channels simultaneously—marks a turning point in this journey. These systems don't just understand spoken words; they interpret tone, recognize images, respond to gestures, and maintain context across different interaction modes. As Dr. Maya Ramirez, director of conversational AI research at Stanford, notes, "We're moving from teaching humans to speak computer to teaching computers to understand humans."
This shift hasn't happened overnight. It's been driven by convergent advances in speech recognition, natural language processing, computer vision, and deep learning. The result is technology that's becoming increasingly invisible—weaving itself into our daily lives without requiring us to adapt our natural behavior.
This evolution represents one of the most significant shifts in human-computer interaction since the graphical user interface replaced command lines. For decades, we adapted our behavior to accommodate technology's limitations—typing precisely formatted commands, navigating complex menu structures, and learning specialized interfaces. Now, technology is finally adapting to our natural communication methods.
The rise of multimodal chatbots—AI systems that can process and respond through multiple channels simultaneously—marks a turning point in this journey. These systems don't just understand spoken words; they interpret tone, recognize images, respond to gestures, and maintain context across different interaction modes. As Dr. Maya Ramirez, director of conversational AI research at Stanford, notes, "We're moving from teaching humans to speak computer to teaching computers to understand humans."
This shift hasn't happened overnight. It's been driven by convergent advances in speech recognition, natural language processing, computer vision, and deep learning. The result is technology that's becoming increasingly invisible—weaving itself into our daily lives without requiring us to adapt our natural behavior.
Beyond Text: The Multimodal Revolution
Traditional chatbots operated exclusively through text, requiring users to type queries and read responses. While text remains a powerful medium, human communication has always been richer and more nuanced. We speak with varying tones, emphasize with gestures, clarify with images, and understand through context. Multimodal AI aims to capture this full spectrum of communication.
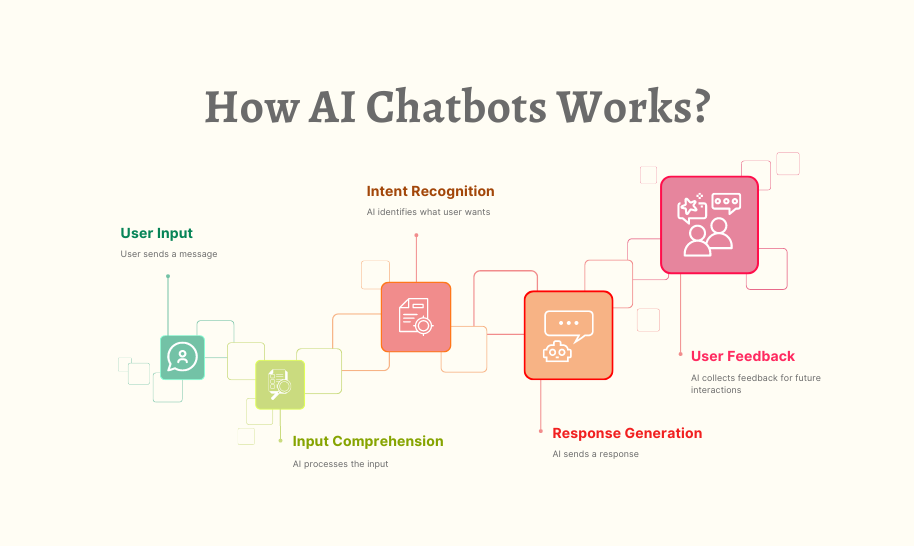
Modern voice-enabled chatbots combine several distinct capabilities:
Speech recognition transforms spoken language into text with increasingly impressive accuracy, even in noisy environments or with diverse accents and dialects.
Natural language understanding extracts meaning and intent from the words, recognizing entities, relationships, and the contextual nuances that give language its richness.
Speech synthesis generates increasingly natural-sounding responses, with appropriate pacing, emphasis, and even emotional undertones that make interactions feel more human.
Visual processing allows systems to receive, interpret, and generate images, videos, and other visual information that complements verbal communication.
Contextual memory maintains an understanding of conversation history across different modes, enabling more coherent and relevant interactions over time.
The integration of these capabilities creates experiences that feel fundamentally different from earlier AI interactions. Take virtual shopping assistants, for example. A customer can now ask to see "something like this but in blue," while showing an image of a dress. The assistant can understand the visual reference, process the verbal modification, and respond with both visual and spoken information about available options.
I recently watched my 78-year-old neighbor, who struggles with technology, have a complex conversation with her multimodal assistant about rescheduling medical appointments while simultaneously reviewing calendar conflicts on her display. The natural flow between voice, visuals, and text made the interaction accessible in a way that would have been impossible with traditional interfaces.
Modern voice-enabled chatbots combine several distinct capabilities:
Speech recognition transforms spoken language into text with increasingly impressive accuracy, even in noisy environments or with diverse accents and dialects.
Natural language understanding extracts meaning and intent from the words, recognizing entities, relationships, and the contextual nuances that give language its richness.
Speech synthesis generates increasingly natural-sounding responses, with appropriate pacing, emphasis, and even emotional undertones that make interactions feel more human.
Visual processing allows systems to receive, interpret, and generate images, videos, and other visual information that complements verbal communication.
Contextual memory maintains an understanding of conversation history across different modes, enabling more coherent and relevant interactions over time.
The integration of these capabilities creates experiences that feel fundamentally different from earlier AI interactions. Take virtual shopping assistants, for example. A customer can now ask to see "something like this but in blue," while showing an image of a dress. The assistant can understand the visual reference, process the verbal modification, and respond with both visual and spoken information about available options.
I recently watched my 78-year-old neighbor, who struggles with technology, have a complex conversation with her multimodal assistant about rescheduling medical appointments while simultaneously reviewing calendar conflicts on her display. The natural flow between voice, visuals, and text made the interaction accessible in a way that would have been impossible with traditional interfaces.
Voice as the Primary Interface
Voice has emerged as perhaps the most transformative element of multimodal systems, fundamentally changing how we interact with technology. There are several reasons voice interfaces have gained such prominence:
Accessibility is significantly improved. Voice interfaces open technology to people with visual impairments, limited mobility, or low literacy, as well as those who find traditional text interfaces challenging due to age or disability.
Hands-free operation enables interaction while driving, cooking, exercising, or performing other activities where using a screen would be impractical or unsafe.
Interaction speed often exceeds typing, particularly for complex queries or commands. Most people speak at 150 words per minute but type at only 40 words per minute.
Natural engagement removes the learning curve associated with specialized interfaces. If you can hold a conversation, you can use a voice-enabled system.
Emotional connection tends to be stronger with voice interactions than text. The human voice carries emotional cues that create a sense of social presence even when interacting with AI.
Sarah Johnson, UX director at a major automotive company, told me how their implementation of multimodal interfaces changed driver behavior: "When we replaced touch screens with voice controls enhanced by simple visual confirmation, we saw distracted driving incidents decrease by over 30%. Drivers kept their eyes on the road while still accessing navigation, entertainment, and communication features."
Voice interfaces aren't without challenges. Privacy concerns arise when devices are always listening, ambient noise can interfere with recognition, and public usage can be socially awkward. However, technological improvements and thoughtful design have addressed many of these issues, contributing to the rapid adoption of voice as a primary interaction method.
Accessibility is significantly improved. Voice interfaces open technology to people with visual impairments, limited mobility, or low literacy, as well as those who find traditional text interfaces challenging due to age or disability.
Hands-free operation enables interaction while driving, cooking, exercising, or performing other activities where using a screen would be impractical or unsafe.
Interaction speed often exceeds typing, particularly for complex queries or commands. Most people speak at 150 words per minute but type at only 40 words per minute.
Natural engagement removes the learning curve associated with specialized interfaces. If you can hold a conversation, you can use a voice-enabled system.
Emotional connection tends to be stronger with voice interactions than text. The human voice carries emotional cues that create a sense of social presence even when interacting with AI.
Sarah Johnson, UX director at a major automotive company, told me how their implementation of multimodal interfaces changed driver behavior: "When we replaced touch screens with voice controls enhanced by simple visual confirmation, we saw distracted driving incidents decrease by over 30%. Drivers kept their eyes on the road while still accessing navigation, entertainment, and communication features."
Voice interfaces aren't without challenges. Privacy concerns arise when devices are always listening, ambient noise can interfere with recognition, and public usage can be socially awkward. However, technological improvements and thoughtful design have addressed many of these issues, contributing to the rapid adoption of voice as a primary interaction method.
Real-World Applications Transforming Industries
The integration of voice capabilities into multimodal chatbots is creating transformative applications across numerous industries:
In healthcare, voice-enabled assistants help patients describe symptoms while simultaneously analyzing visual cues like skin conditions or movement limitations. Doctors at Massachusetts General Hospital reported that their AI triage system, which combines voice interviews with image analysis, improved initial diagnosis accuracy by 22% compared to standard questionnaires.
Customer service has been revolutionized through systems that seamlessly transition between voice calls, text chats, and visual demonstrations. When a customer calls with a complex product issue, these systems can switch to sending instructional videos or requesting photos of the problem, all while maintaining conversational continuity.
Educational applications use voice interaction combined with visual materials to create more engaging and accessible learning experiences. A language learning app I recently tested uses speech recognition to evaluate pronunciation while simultaneously showing mouth positioning and offering visual representations of concepts—creating a multi-sensory learning environment.
Retail environments now feature virtual assistants that can discuss products, show comparisons, and process purchases through natural conversation. Nordstrom's in-store voice assistants can understand queries like "Show me something similar to what I bought last month, but warmer for winter," pulling purchase history and making contextually relevant recommendations.
Industrial applications combine voice commands with visual confirmation in environments where hands-free operation is crucial. Factory workers at a Boeing assembly facility use voice-directed systems that provide visual guidance for complex assembly tasks, reducing errors by 17% while increasing efficiency.
Smart home ecosystems increasingly rely on multimodal interactions, allowing users to control environments through natural speech while receiving visual feedback. "Show me who's at the front door" triggers both a verbal response and a camera feed display, creating a more complete awareness of the home environment.
The most successful implementations don't treat voice as merely an additional input method but redesign the entire interaction model around natural communication patterns. This holistic approach yields experiences that feel intuitive rather than technological.
In healthcare, voice-enabled assistants help patients describe symptoms while simultaneously analyzing visual cues like skin conditions or movement limitations. Doctors at Massachusetts General Hospital reported that their AI triage system, which combines voice interviews with image analysis, improved initial diagnosis accuracy by 22% compared to standard questionnaires.
Customer service has been revolutionized through systems that seamlessly transition between voice calls, text chats, and visual demonstrations. When a customer calls with a complex product issue, these systems can switch to sending instructional videos or requesting photos of the problem, all while maintaining conversational continuity.
Educational applications use voice interaction combined with visual materials to create more engaging and accessible learning experiences. A language learning app I recently tested uses speech recognition to evaluate pronunciation while simultaneously showing mouth positioning and offering visual representations of concepts—creating a multi-sensory learning environment.
Retail environments now feature virtual assistants that can discuss products, show comparisons, and process purchases through natural conversation. Nordstrom's in-store voice assistants can understand queries like "Show me something similar to what I bought last month, but warmer for winter," pulling purchase history and making contextually relevant recommendations.
Industrial applications combine voice commands with visual confirmation in environments where hands-free operation is crucial. Factory workers at a Boeing assembly facility use voice-directed systems that provide visual guidance for complex assembly tasks, reducing errors by 17% while increasing efficiency.
Smart home ecosystems increasingly rely on multimodal interactions, allowing users to control environments through natural speech while receiving visual feedback. "Show me who's at the front door" triggers both a verbal response and a camera feed display, creating a more complete awareness of the home environment.
The most successful implementations don't treat voice as merely an additional input method but redesign the entire interaction model around natural communication patterns. This holistic approach yields experiences that feel intuitive rather than technological.
The Technology Behind the Transformation
The capabilities of today's multimodal chatbots result from remarkable advances across multiple technical domains:
Advanced speech recognition now achieves over 95% accuracy in ideal conditions thanks to deep neural networks trained on massive datasets of human speech. These systems can handle different accents, dialects, speech impediments, and background noise with increasing robustness.
Natural language understanding has evolved from simple keyword matching to sophisticated models that grasp context, intention, and subtlety. Modern systems understand ambiguous references, track entities across a conversation, and interpret implicit meanings that aren't directly stated.
Large language models (LLMs) provide the foundation for many multimodal systems, with architectures that can process and generate both text and other modalities. These models contain hundreds of billions of parameters and are trained on diverse data that helps them understand relationships between different types of information.
Speech synthesis has progressed from robotic, disconnected phonemes to natural-sounding voices with appropriate emotional inflection and timing. The best systems now pass the "uncanny valley," sounding human enough that users forget they're speaking with AI.
Computer vision capabilities allow systems to recognize objects, interpret scenes, understand gestures, and process visual information that complements voice interaction. When you ask a multimodal assistant about an object you're holding up to the camera, multiple AI systems work in concert to deliver a coherent response.
Edge computing advancements have enabled more processing to happen directly on devices rather than in the cloud, reducing latency and addressing privacy concerns about sending all voice data to remote servers.
Mark Chen, chief technology officer at a leading conversational AI company, explained, "The real breakthrough wasn't any single technology but the integration of multiple AI systems that can share context and collaborate in real-time. When your voice assistant can both hear your question about a rash on your arm and see the rash itself, the diagnostic capability increases exponentially."
While individual components like speech recognition have improved dramatically, the seamless orchestration of these technologies creates experiences greater than the sum of their parts. The most advanced systems dynamically determine which modalities are most appropriate for different parts of an interaction, switching fluidly between them based on context and user needs.
Advanced speech recognition now achieves over 95% accuracy in ideal conditions thanks to deep neural networks trained on massive datasets of human speech. These systems can handle different accents, dialects, speech impediments, and background noise with increasing robustness.
Natural language understanding has evolved from simple keyword matching to sophisticated models that grasp context, intention, and subtlety. Modern systems understand ambiguous references, track entities across a conversation, and interpret implicit meanings that aren't directly stated.
Large language models (LLMs) provide the foundation for many multimodal systems, with architectures that can process and generate both text and other modalities. These models contain hundreds of billions of parameters and are trained on diverse data that helps them understand relationships between different types of information.
Speech synthesis has progressed from robotic, disconnected phonemes to natural-sounding voices with appropriate emotional inflection and timing. The best systems now pass the "uncanny valley," sounding human enough that users forget they're speaking with AI.
Computer vision capabilities allow systems to recognize objects, interpret scenes, understand gestures, and process visual information that complements voice interaction. When you ask a multimodal assistant about an object you're holding up to the camera, multiple AI systems work in concert to deliver a coherent response.
Edge computing advancements have enabled more processing to happen directly on devices rather than in the cloud, reducing latency and addressing privacy concerns about sending all voice data to remote servers.
Mark Chen, chief technology officer at a leading conversational AI company, explained, "The real breakthrough wasn't any single technology but the integration of multiple AI systems that can share context and collaborate in real-time. When your voice assistant can both hear your question about a rash on your arm and see the rash itself, the diagnostic capability increases exponentially."
While individual components like speech recognition have improved dramatically, the seamless orchestration of these technologies creates experiences greater than the sum of their parts. The most advanced systems dynamically determine which modalities are most appropriate for different parts of an interaction, switching fluidly between them based on context and user needs.
Test AI on YOUR Website in 60 Seconds
See how our AI instantly analyzes your website and creates a personalized chatbot - without registration. Just enter your URL and watch it work!
Ready in 60 seconds
No coding required
100% secure
Ethical Considerations and Societal Impact
As voice-enabled multimodal AI becomes more integrated into daily life, important ethical questions and societal implications emerge:
Privacy concerns are particularly acute with always-listening devices in homes and workplaces. Users often don't fully understand when their conversations are being recorded, processed, or stored. Companies must navigate the balance between functionality that requires listening and respect for private spaces.
Accessibility benefits can be transformative for people with disabilities, but only if these systems are designed with diverse needs in mind from the beginning. Voice interfaces that can't understand accents or speech impediments may actually widen the digital divide rather than narrowing it.
Social norms around AI interaction are still evolving. As voice assistants become more human-like, users may develop emotional attachments or expectations that these systems aren't designed to fulfill. The line between helpful tool and perceived social relationship can blur.
Labor market disruption is inevitable as voice AI systems replace certain roles in customer service, reception, and other interaction-heavy positions. While new jobs will emerge, the transition may be difficult for workers whose skills are suddenly less in demand.
Algorithmic bias can manifest in voice systems that understand certain accents, dialects, or speech patterns better than others. If these systems perform poorly for specific demographic groups, existing inequalities may be reinforced.
Technology dependency raises questions about what happens when we outsource more cognitive and interactive functions to AI systems. Some researchers express concern about atrophy of certain human capabilities as we rely more heavily on technological assistance.
Dr. Elena Washington, an AI ethicist, shared her perspective: "Voice AI is inherently more intimate than text interfaces. It enters our homes, listens to our conversations, and speaks to us in human-like voices. This creates both opportunity and responsibility. These systems need ethical guardrails that match their unprecedented access to our lives."
Forward-thinking organizations are addressing these concerns through transparency about data usage, opt-in policies for voice recording, diverse training data to reduce bias, and clear signaling when users are interacting with AI rather than humans. The industry is gradually recognizing that long-term success depends not just on technical capability but on earning and maintaining user trust.
Privacy concerns are particularly acute with always-listening devices in homes and workplaces. Users often don't fully understand when their conversations are being recorded, processed, or stored. Companies must navigate the balance between functionality that requires listening and respect for private spaces.
Accessibility benefits can be transformative for people with disabilities, but only if these systems are designed with diverse needs in mind from the beginning. Voice interfaces that can't understand accents or speech impediments may actually widen the digital divide rather than narrowing it.
Social norms around AI interaction are still evolving. As voice assistants become more human-like, users may develop emotional attachments or expectations that these systems aren't designed to fulfill. The line between helpful tool and perceived social relationship can blur.
Labor market disruption is inevitable as voice AI systems replace certain roles in customer service, reception, and other interaction-heavy positions. While new jobs will emerge, the transition may be difficult for workers whose skills are suddenly less in demand.
Algorithmic bias can manifest in voice systems that understand certain accents, dialects, or speech patterns better than others. If these systems perform poorly for specific demographic groups, existing inequalities may be reinforced.
Technology dependency raises questions about what happens when we outsource more cognitive and interactive functions to AI systems. Some researchers express concern about atrophy of certain human capabilities as we rely more heavily on technological assistance.
Dr. Elena Washington, an AI ethicist, shared her perspective: "Voice AI is inherently more intimate than text interfaces. It enters our homes, listens to our conversations, and speaks to us in human-like voices. This creates both opportunity and responsibility. These systems need ethical guardrails that match their unprecedented access to our lives."
Forward-thinking organizations are addressing these concerns through transparency about data usage, opt-in policies for voice recording, diverse training data to reduce bias, and clear signaling when users are interacting with AI rather than humans. The industry is gradually recognizing that long-term success depends not just on technical capability but on earning and maintaining user trust.
User Experience Design Challenges
Creating effective voice-enabled multimodal experiences presents unique design challenges that differ significantly from traditional interface design:
Conversation design requires a fundamentally different approach than visual interface design. Conversations are temporal rather than spatial, with users unable to "scan" available options as they would on a screen. Designers must create experiences that guide users naturally without overwhelming them with choices or information.
Error handling becomes more complex when voice is the primary interface. Unlike a misclick that can be immediately corrected, speech recognition errors can derail entire interactions. Effective systems must gracefully confirm critical information and provide recovery paths when misunderstandings occur.
Multimodal coordination requires careful orchestration of different communication channels. When should information be presented visually versus verbally? How do these channels complement rather than compete with each other? These questions require thoughtful design decisions based on cognitive principles and user testing.
Personality and tone significantly impact user perception of voice interfaces. Unlike visual interfaces where personality is less prominent, voice naturally conveys character traits. Organizations must decide what personality attributes align with their brand and implement them consistently.
Context awareness becomes essential for natural interactions. Systems need to understand not just what users say but when and where they say it, adjusting responses based on environmental factors, time of day, user history, and other contextual elements.
Jamie Rivera, who leads voice experience design at a major technology company, described their approach: "We spent months determining when to use voice alone, when to add visual elements, and when to transition users to a screen-primary experience. The right answer varies not just by task but by user, environment, and context. Our design system now includes decision trees for modality selection that account for dozens of variables."
The most successful designs don't simply translate screen-based interactions to voice but rethink the entire interaction model based on conversation principles. This often means fewer options presented at once, more confirmation of critical actions, and careful attention to memory limitations in audio-only contexts.
Conversation design requires a fundamentally different approach than visual interface design. Conversations are temporal rather than spatial, with users unable to "scan" available options as they would on a screen. Designers must create experiences that guide users naturally without overwhelming them with choices or information.
Error handling becomes more complex when voice is the primary interface. Unlike a misclick that can be immediately corrected, speech recognition errors can derail entire interactions. Effective systems must gracefully confirm critical information and provide recovery paths when misunderstandings occur.
Multimodal coordination requires careful orchestration of different communication channels. When should information be presented visually versus verbally? How do these channels complement rather than compete with each other? These questions require thoughtful design decisions based on cognitive principles and user testing.
Personality and tone significantly impact user perception of voice interfaces. Unlike visual interfaces where personality is less prominent, voice naturally conveys character traits. Organizations must decide what personality attributes align with their brand and implement them consistently.
Context awareness becomes essential for natural interactions. Systems need to understand not just what users say but when and where they say it, adjusting responses based on environmental factors, time of day, user history, and other contextual elements.
Jamie Rivera, who leads voice experience design at a major technology company, described their approach: "We spent months determining when to use voice alone, when to add visual elements, and when to transition users to a screen-primary experience. The right answer varies not just by task but by user, environment, and context. Our design system now includes decision trees for modality selection that account for dozens of variables."
The most successful designs don't simply translate screen-based interactions to voice but rethink the entire interaction model based on conversation principles. This often means fewer options presented at once, more confirmation of critical actions, and careful attention to memory limitations in audio-only contexts.
The Future Landscape: Emerging Trends
As multimodal AI continues to evolve, several emerging trends are shaping the future landscape:
Emotional intelligence is becoming a key differentiator as systems move beyond functional accuracy to recognizing and responding appropriately to human emotions. Advanced voice systems detect frustration, confusion, or delight in user voices and adjust their responses accordingly.
Personalization is growing more sophisticated as systems build comprehensive user models across interactions. Rather than treating each conversation as isolated, future systems will understand user preferences, communication styles, and needs over time, creating increasingly tailored experiences.
Ambient intelligence envisions environments where voice and multimodal AI blend seamlessly into physical spaces, available when needed but invisible when not. Instead of explicitly activating devices, users will navigate an environment responsive to natural communication.
Specialized voice interfaces are emerging for specific domains like healthcare, legal, and education, with deep knowledge of field-specific terminology and workflows. These specialized systems achieve higher accuracy and usefulness within their domains than general-purpose assistants.
Decentralized voice AI is gaining traction as privacy concerns drive development of systems that process voice locally rather than sending data to cloud servers. This approach reduces latency while keeping potentially sensitive voice data on user devices.
Cross-device continuity allows conversations to flow naturally across different environments and devices. A conversation started with a smart speaker can transition seamlessly to a car, then to a phone, with full context maintained throughout.
Professor Tariq Johnson, who researches next-generation interfaces at MIT Media Lab, predicts: "Within five years, the distinction between different modes of interaction will become almost meaningless to users. They'll simply communicate naturally, and their technological environment will respond appropriately, sometimes through voice, sometimes visually, sometimes haptically—often through combinations determined by the specifics of the situation."
This convergence suggests a future where the technology itself recedes from awareness, and human attention focuses on tasks and goals rather than the interfaces used to accomplish them.
Emotional intelligence is becoming a key differentiator as systems move beyond functional accuracy to recognizing and responding appropriately to human emotions. Advanced voice systems detect frustration, confusion, or delight in user voices and adjust their responses accordingly.
Personalization is growing more sophisticated as systems build comprehensive user models across interactions. Rather than treating each conversation as isolated, future systems will understand user preferences, communication styles, and needs over time, creating increasingly tailored experiences.
Ambient intelligence envisions environments where voice and multimodal AI blend seamlessly into physical spaces, available when needed but invisible when not. Instead of explicitly activating devices, users will navigate an environment responsive to natural communication.
Specialized voice interfaces are emerging for specific domains like healthcare, legal, and education, with deep knowledge of field-specific terminology and workflows. These specialized systems achieve higher accuracy and usefulness within their domains than general-purpose assistants.
Decentralized voice AI is gaining traction as privacy concerns drive development of systems that process voice locally rather than sending data to cloud servers. This approach reduces latency while keeping potentially sensitive voice data on user devices.
Cross-device continuity allows conversations to flow naturally across different environments and devices. A conversation started with a smart speaker can transition seamlessly to a car, then to a phone, with full context maintained throughout.
Professor Tariq Johnson, who researches next-generation interfaces at MIT Media Lab, predicts: "Within five years, the distinction between different modes of interaction will become almost meaningless to users. They'll simply communicate naturally, and their technological environment will respond appropriately, sometimes through voice, sometimes visually, sometimes haptically—often through combinations determined by the specifics of the situation."
This convergence suggests a future where the technology itself recedes from awareness, and human attention focuses on tasks and goals rather than the interfaces used to accomplish them.
Conclusion: The Conversational Future
The rise of voice-enabled multimodal chatbots represents more than just another technological advancement—it signals a fundamental shift in our relationship with technology. After decades of humans adapting to technological limitations, we're entering an era where technology adapts to natural human communication patterns.
This transformation carries profound implications. For users, it means more intuitive, accessible, and efficient interactions. For developers and designers, it requires rethinking interaction models around conversation rather than manipulation. For organizations, it offers opportunities to create more personal, engaging relationships with customers while navigating new privacy and ethical considerations.
The most successful implementations will be those that thoughtfully combine different modalities based on context, user needs, and environmental factors. Voice will often lead these interactions, but visual, gestural, and text components will complement speech in ways that leverage the strengths of each communication channel.
As these systems continue to evolve, the line between digital and physical interactions will blur further. Our digital assistants will become more contextually aware, emotionally intelligent, and personally tailored to our individual needs. The technology itself will increasingly fade into the background as the experience becomes more naturally human.
The conversational future promised by science fiction for decades is finally emerging—not through any single breakthrough but through the careful integration of advances across multiple domains. Voice-enabled multimodal AI isn't just changing how we interact with technology; it's redefining what technology interaction means in our daily lives.
This transformation carries profound implications. For users, it means more intuitive, accessible, and efficient interactions. For developers and designers, it requires rethinking interaction models around conversation rather than manipulation. For organizations, it offers opportunities to create more personal, engaging relationships with customers while navigating new privacy and ethical considerations.
The most successful implementations will be those that thoughtfully combine different modalities based on context, user needs, and environmental factors. Voice will often lead these interactions, but visual, gestural, and text components will complement speech in ways that leverage the strengths of each communication channel.
As these systems continue to evolve, the line between digital and physical interactions will blur further. Our digital assistants will become more contextually aware, emotionally intelligent, and personally tailored to our individual needs. The technology itself will increasingly fade into the background as the experience becomes more naturally human.
The conversational future promised by science fiction for decades is finally emerging—not through any single breakthrough but through the careful integration of advances across multiple domains. Voice-enabled multimodal AI isn't just changing how we interact with technology; it's redefining what technology interaction means in our daily lives.